の4項目となっている。花びらは漢字で書くと「花弁」であり「かべん」とも読む。花の上部にあるのが「花びら」で、下部にあるのが「がく片」となる。あやめの場合、「花びらよりもがく片の方が大きく、がく片が花のような形と色彩である」という特徴があるので注意してほしい。図2は論文「The Species Problem in Iris」(1936年)から引用した図で、2つずつ並ぶ左の大きい方がSepal(がく片)で小さい方がPetal(花びら)となっている。
図2 3種類のあやめが持つ花びら/がく片のスケッチ(論文「The Species Problem in Iris」から引用)※引用元: 論文「The Species Problem in Iris」(1936年)
このデータセットは、基本的に自由に使用できる(※UCI Machine Learning Repositoryでは、ライセンスとしてCC BY 4.0が指定されている。データの取得元を明記する場合は、以下を参考にしてほしい)。
論文著者: R.A. Fisherタイトル: The use of multiple measurements in taxonomic problems, Annual Eugenics, 7, Part II, 179-188.公開年: 1936(※下記リンク先に、このデータセットがUCI Machine Learning Repositoryに提出されたのは1988年7月1日との記載がある)URL: https://archive-beta.ics.uci.edu/ml/datasets/iris
Ronald Aylmer Fisher氏は、20世紀の統計学者/生物学者として非常に有名なフィッシャーのことである。このため、「Fisher's Iris dataset(フィッシャーのあやめデータセット)」と呼ばれることもある。
また、元々のデータ収集はEdgar Anderson氏が行っているため(参考:「The Species Problem in Iris」、1936年)、「Anderson's Iris dataset(アンダーソンのあやめデータセット)」と呼ばれることもある。

 図1 Irisデータセットの内容例※データセットの配布元: 「https://archive-beta.ics.uci.edu/ml/datasets/iris」。ライセンスはCC BY 4.0。
図1 Irisデータセットの内容例※データセットの配布元: 「https://archive-beta.ics.uci.edu/ml/datasets/iris」。ライセンスはCC BY 4.0。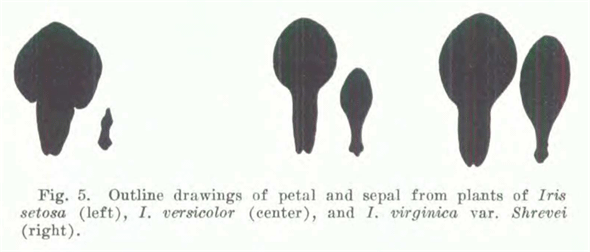 図2 3種類のあやめが持つ花びら/がく片のスケッチ(論文「The Species Problem in Iris」から引用)※引用元: 論文「The Species Problem in Iris」(1936年)
図2 3種類のあやめが持つ花びら/がく片のスケッチ(論文「The Species Problem in Iris」から引用)※引用元: 論文「The Species Problem in Iris」(1936年)仮想通貨カジノパチンコストレート セブン パチンコ")
仮想通貨カジノパチンコストレート セブン パチンコ")










